
【簡単エクセル/Excel VBA マクロ】Mac環境でデータの重複を検出する方法|配列活用/Dictionary不使用|ワンポイントテクニック #014
 ポテ
ポテ

いつもありがとうございます。
皆さん、こんにちは。ご覧いただきありがとうございます。
“日々の業務にちょうどいい自動化を”──
業務改善アプリケーションの開発を行っている ソフトデザイン工房 です。
この記事では「Mac環境でデータの重複を検出する方法」を解説します。
実は以前、Dictionary オブジェクトを使用してデータの重複を検出する方法をご紹介しました。
重複データの検出と言えば、Dictionary オブジェクトを使うのが定番です。
コードもシンプルに書けますし、スマートに仕上がります。

しかし、Macで使うには、ひとつ問題があります。
Dictionary オブジェクトは、Mac環境では使用できないのです。
これは、Scripting.Dictionary が Windows に搭載されている「Windows Script Host(WSH)」という仕組みに依存しているためです。
つまり、Mac 版 Excel ではサポートされていないのです。
では、Mac ユーザーはどのようにすればよいのでしょうか。
答えは、Dictionary を使わずに、ローレベルな配列操作だけで実装することです。
そこでこの記事では、配列だけを使って重複データを検出する方法を、2つのアプローチでご紹介します。
どちらも Dictionary を使わないため、Mac でも安心して動作する構成になっています。
この記事が、あなたのVBAマクロの価値をさらに高める一助となれば幸いです。
VBAを活用して、自分自身や身近なコミュニティに合ったアプリケーションを作成し、仕事量は半分に、成果は2倍に──そんな未来を目指すあなたを応援しています。
Macで重複データを検出する2つの方法

【方法1】ユニーク配列方式
これは、値を一つひとつ「記録しておく箱(配列)」に入れておき、あとから同じ値が出てきたら「おっ、さっきもあったね」と判断する方法です。
すでにある値には、何行目に出てきたかをカンマ区切りでメモしていきます。記録しながら比較するので、処理が速く、効率的です。
【方法2】総当たり比較方式
こちらは、たとえるなら「全員に自己紹介をして、同じ名前の人がいないか全員に聞いて回る」ような方法です。
まず1行目の値を2行目以降すべてと比べ、次に2行目を3行目以降と比べ…という風に、全データを一つずつ総当たりで比較していきます。
こちらは、方法1と比べると、やや処理時間がかかる仕組みですが、気にならないレベルです。
仕組みがシンプルで、処理の流れが直感的に理解しやすいのが特長です。
具体例と解説
シナリオ
ここでは、「A列に入力された名前の中から、重複しているものを検出したい」という場面を例に取ります。具体的には、次のような表を扱います。
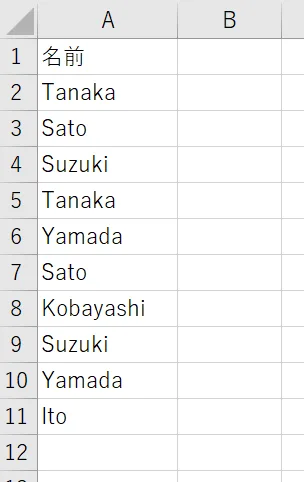
シートに記載されている「Tanaka」や「Sato」のように複数回登場している名前を検出し、それぞれが何行目に現れたかを把握したい、というケースです。
この記事では、このような重複検出を 配列を使った2つの異なる方法で実装し、それぞれのコードの構造と動作の違いを解説していきます。
【方法1】ユニーク配列方式

このコードは、ユニーク(一意)な値とそれに対応する行番号をそれぞれ別の配列に保持することで、効率よく重複を追跡する方法です。
処理の流れ
セルを1つずつ処理するのではなく、いったんすべてを読み込んで、 その後は配列だけを使って処理を進めることで、高速化を図ります。
重複している値の「行番号」の情報を、「行格納用配列」記録していきます。
たとえば「banana」という値が3行目と5行目にあった場合、"3,5" というふうに記録していきます。
はじめて出てきた値であれば、その値を「ユニーク値配列」に記録していきます。
出現行が複数あるもの(=行格納用配列にカンマが含まれるもの)だけを「重複あり」とみなして出力します。
コードと解説
【コード】
まずコードを示します。
Option Explicit
Sub DetectDuplicate1()
' 変数宣言
Dim wb As Workbook
Dim ws As Worksheet
Dim last_row As Long ' データの最終行
Dim data_rng As Range ' データ範囲
Dim data_arr As Variant ' データ範囲を格納する配列
Dim data_arr_row As Long ' データ配列用行インデックス
Dim current_value As String ' 現在処理中の値
Dim already_recorded As Boolean ' 値が登録済みかを判定するフラグ
Dim unique_values_arr() As String ' ユニーク値格納用配列
Dim rows_arr() As String ' 「行」格納用配列
Dim unique_value_arr_idx As Long ' ユニーク値格納用配列のインデックス
Dim unique_count As Long ' 登録済み値の個数
' ワークブックとワークシートを取得する
Set wb = ThisWorkbook
Set ws = wb.Worksheets(1)
' データの最終行を取得
last_row = ws.Cells(ws.Cells.Rows.Count, 1).End(xlUp).Row
' 対象データを配列に読み込む(二次元配列)
Set data_rng = ws.Range(ws.Cells(2, 1), ws.Cells(last_row, 1))
data_arr = data_rng.Value
' ユニーク値・行格納用配列を初期化
ReDim unique_values_arr(1 To 1)
ReDim rows_arr(1 To 1)
unique_count = 0
' データ配列の行をループ
For data_arr_row = 1 To UBound(data_arr, 1)
' 現在値を変数に格納
current_value = CStr(data_arr(data_arr_row, 1))
' 値が登録済みかを判定するフラグを初期化
already_recorded = False
' ユニーク値配列をループ
For unique_value_arr_idx = 1 To unique_count
' ユニーク値配列に登録済みであれば(配列の値と現在値が一致したら)
If unique_values_arr(unique_value_arr_idx) = current_value Then
' 「行」配列に行番号を追加
' ※データ範囲がA2からなので "data_arr_row +1"
rows_arr(unique_value_arr_idx) = _
rows_arr(unique_value_arr_idx) & "," & (data_arr_row + 1)
already_recorded = True
Exit For
End If
Next unique_value_arr_idx
' ユニーク値配列に登録されていなければ
If Not already_recorded Then
' 登録済みの値の個数をインクリメント
unique_count = unique_count + 1
' 配列のサイズを調整
ReDim Preserve unique_values_arr(1 To unique_count)
ReDim Preserve rows_arr(1 To unique_count)
' 配列に値と行を格納
unique_values_arr(unique_count) = current_value
rows_arr(unique_count) = CStr(data_arr_row + 1)
End If
Next data_arr_row
' 重複情報を出力
For unique_value_arr_idx = 1 To unique_count
' 行番号情報に","を含んでいたら
If rows_arr(unique_value_arr_idx) Like "*,*" Then
Debug.Print unique_values_arr(unique_value_arr_idx) & _
" " & _
rows_arr(unique_value_arr_idx)
End If
Next unique_value_arr_idx
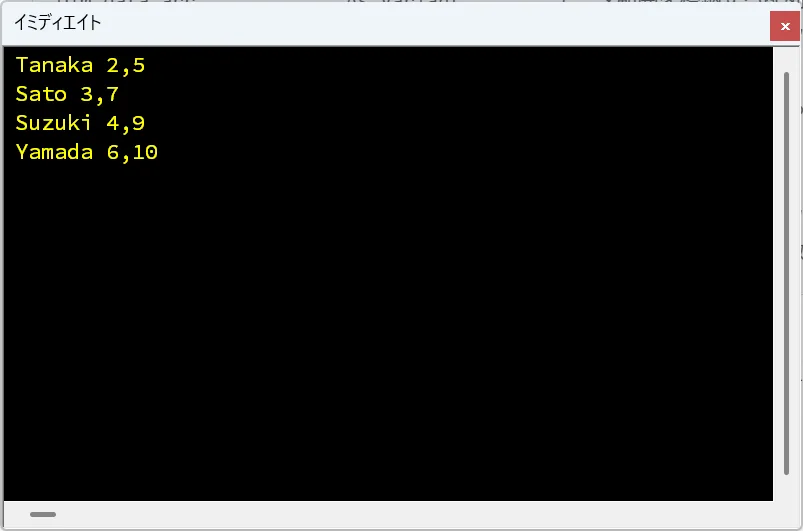
End Sub【出力結果】
このコードを実行すると、次の結果が返ります。
解説していきます。
Option Expliciここでは、Option Explicit を有効にしています。
この設定を使うと、変数を使用する前に必ず宣言が必要になります。
これにより、変数のタイプミスや未定義変数によるエラーを防ぎ、コードの安全性と信頼性を高めることができます。
' 変数宣言
Dim wb As Workbook
Dim ws As Worksheet
Dim last_row As Long ' データの最終行
Dim data_rng As Range ' データ範囲
Dim data_arr As Variant ' データ範囲を格納する配列
Dim data_arr_row As Long ' データ配列用行インデックス
Dim current_value As String ' 現在処理中の値
Dim already_recorded As Boolean ' 値が登録済みかを判定するフラグ
Dim unique_values_arr() As String ' ユニーク値格納用配列
Dim rows_arr() As String ' 「行」格納用配列
Dim unique_value_arr_idx As Long ' ユニーク値格納用配列のインデックス
Dim unique_count As Long ' 登録済み値の個数ここでは、コード内で使用する変数を宣言しています。
変数は Dim 変数名 As データ型 の構文で宣言します。これにより、各変数は As 以降で指定したデータ型の値を格納できるようになります。
具体的には、現在のワークブックやワークシートを操作するためのオブジェクト型の変数、処理対象のデータを保持するための配列、ユニーク値の登録と照合に使うインデックスやフラグなどを宣言しています。
また、コードの可読性を高めるため、変数は用途別にグループ化して記述しています。こうすることで、どの変数がどの処理に関わっているのかが一目で把握できるようになります。
なお、各データ型の意味は下表のとおりです。
| データ型 | 種類 | 意味 |
|---|---|---|
Workbook | オブジェクト型 | 現在のワークブックやデータが格納されているワークブックを表すオブジェクトです。 |
Worksheet | オブジェクト型 | データが格納されているワークシートを表すオブジェクト型です。 |
String | 文字列型 | ファイルパスや名前など、テキスト情報を格納する文字列型です。 |
Long | 数値型 | -2,147,483,648 〜 2,147,483,647 の範囲の整数を格納できる数値型です。 |
Variant | 汎用型 | 任意のデータ型を格納できる柔軟な型で、配列や複数の型に対応する場面で使用されます。 |
' ワークブックとワークシートを取得する
Set wb = ThisWorkbook
Set ws = wb.Worksheets(1)ここでは、マクロを含んだワークブック(ThisWorkbook)から、最初のワークシート(インデックス番号1)を取得して、変数 ws に代入しています。
通常、Excel には複数のワークシートが存在するため、どのシートを対象に処理を行うかを明示する必要があります。
インデックス 1 は、左端にあるシートを意味します。たとえば、シートの並び順が「Sheet1」「Sheet2」「Sheet3」であれば、「Sheet1」が対象になります。
このようにワークシートを変数に代入しておくことで、以降の処理では、変数 ws を通じてワークシートを操作できるようになり、毎回 Worksheets(1) と書かずに済むため、コードの可読性と保守性が向上します。
' データの最終行を取得
last_row = ws.Cells(ws.Cells.Rows.Count, 1).End(xlUp).Rowここでは、A列の最終行番号を取得しています。
ws.Rows.Count はシート内の総行数(通常は 1,048,576)を意味し、ws.Cells(ws.Rows.Count, 1) によって、A列の最下部セルが参照されます。
そこから End(xlUp) を使って上方向に値が入力されているセルを探し、最初に見つかったセルの行番号を last_row に格納しています。
この例の場合は、last_rowには11が代入されます。
' 対象データを配列に読み込む(二次元配列)
Set data_rng = ws.Range(ws.Cells(2, 1), ws.Cells(last_row, 1))
data_arr = data_rng.Valueここでは、A列の2行目から最終行までのデータを範囲として取得し、配列 data_arr に格納しています。
このように範囲を Range オブジェクトとして取得し、そこから .Value を代入することで、Excelのセル範囲を二次元配列として効率的に扱うことができます。
読み込まれる配列は、1行目がシートの2行目に、2行目がシートの3行目に対応する構造になっており、このあと出てくる処理では、「何行目か」を求める際に +1 の補正が行われます。
また、セルを1つずつ読み込むよりも、一括で配列化して処理することで、パフォーマンスが大きく向上します。これは、VBAにおける高速化の基本的な考え方のひとつです。
' ユニーク値・行格納用配列を初期化
ReDim unique_values_arr(1 To 1)
ReDim rows_arr(1 To 1)
unique_count = 0ここでは、ユニークな値(重複していない値)と、それに対応する行番号の一覧を格納するための2つの配列を初期化しています。
ReDim は、配列のサイズを指定して再定義する構文です。
この時点ではまだ値は登録されていないため、いったん 1 To 1 の最小構成で初期化しておきます。
この後、実際のデータ処理の中で必要に応じて ReDim Preserve によりサイズを拡張していくことになります。
また、unique_count はユニーク値がいくつ登録されたかをカウントするための変数で、初期値は 0 に設定されています。このカウントは、後続の処理でループ範囲や配列の添え字として活用されます。
' データ配列の行をループ
For data_arr_row = 1 To UBound(data_arr, 1)
' 現在値を変数に格納
current_value = CStr(data_arr(data_arr_row, 1))
' 値が登録済みかを判定するフラグを初期化
already_recorded = Falseここでは、読み込んだデータ配列 data_arr の各行を、先頭から順に処理しています。
UBound(data_arr, 1) は、配列の1次元目(=行)の最大インデックスを表しており、すなわち配列の最終行を示します。
1行ずつ処理する中で、まず現在の値(1列目の内容)を current_value に文字列として格納し、その後、その値がすでに登録済みかどうかを判定するためのフラグ already_recorded を False に初期化しています。
' ユニーク値配列をループ
For unique_value_arr_idx = 1 To unique_count
' ユニーク値配列に登録済みであれば(配列の値と現在値が一致したら)
If unique_values_arr(unique_value_arr_idx) = current_value Then
' 「行」配列に行番号を追加
' ※データ範囲がA2からなので "data_arr_row +1"
rows_arr(unique_value_arr_idx) = _
rows_arr(unique_value_arr_idx) & "," & (data_arr_row + 1)
already_recorded = True
Exit For
End If
Next unique_value_arr_idxここでは、これまでに記録されたユニーク値と、現在の値を1つずつ照合しています。
もし、すでに同じ値が登録されていれば、 その値の行番号情報(rows_arr)に、現在の行番号をカンマ区切りで追記します。
なお、データの開始行が2行目なので、セルを参照する際にはdata_arr_row + 1 として、行番号を1行分補正しています。
一致する値が見つかった時点で already_recorded を True に切り替え、Exit For によって照合ループを抜けます。
' ユニーク値配列に登録されていなければ
If Not already_recorded Then
' 登録済みの値の個数をインクリメント
unique_count = unique_count + 1
' 配列のサイズを調整
ReDim Preserve unique_values_arr(1 To unique_count)
ReDim Preserve rows_arr(1 To unique_count)
' 配列に値と行を格納
unique_values_arr(unique_count) = current_value
rows_arr(unique_count) = CStr(data_arr_row + 1)
End If
Next data_arr_rowここでは、現在処理している値 current_value が、まだ一度も unique_values_arr に登録されていなかった場合にのみ実行される処理が書かれています。
まず、unique_count を1つ増やすことで、ユニーク値の登録件数を更新します。この値は、配列の要素数の管理にも使われているため、配列の再定義(ReDim Preserve) においても必須です。
ReDim Preserve は、既存の配列の中身を保持したままサイズを変更する構文です。ここでは、ユニーク値と対応する行番号を保持する2つの配列に対して、それぞれ1要素分の空きを追加しています。
最後に、現在の値と、その行番号(データ範囲は2行目から始まるため +1 して補正)を新しく確保した配列の末尾に格納しています。
' 重複情報を出力
For unique_value_arr_idx = 1 To unique_count
' 行番号情報に","を含んでいたら
If rows_arr(unique_value_arr_idx) Like "*,*" Then
Debug.Print unique_values_arr(unique_value_arr_idx) & _
" " & _
rows_arr(unique_value_arr_idx)
End If
Next unique_value_arr_idxここでは、ユニーク値と対応する行番号の一覧から、2回以上出現した値(=重複している値)だけを取り出して出力しています。
rows_arr() にカンマ(,)が含まれているかどうかを、Like "*,*" という構文で判定し、該当するものだけを Debug.Print を使って即時ウィンドウに表示します。
カンマが含まれているということは、つまり、その値が2行以上に登場したことを意味します。
この処理によって、どの値が、どの行で重複していたのかを簡単に確認できるようになります。
以上で、ユニーク配列方式による重複検出コードの解説は終了です。ありがとうございました。
【方法2】総当たり比較方式

このコードは、すべての行のペアを比較することで、重複データを検出する方法です。ユニーク値の配列と、その行番号を記録する配列を用意し、値が一致した組を見つけるたびに記録していきます。
処理の流れ
セルを1つずつ処理するのではなく、いったんすべてを読み込んで、 その後は配列だけを使って処理を進めることで、高速化を図ります。
上から順に1行ずつ「基準行」として取り出し、その下にある行と順番に比べていきます。 同じ値が見つかった場合、それは「重複」として扱います。
重複していた2つの行番号(基準行と検出行)を、「重複値格納用配列」にカンマ区切りで記録します。
重複している値の「行番号」のみを、「行格納用配列」記録していきます。
たとえば「apple」という値が3行目・5行目・8行目にあった場合、"3,5,8" のように記録されます。
重複値配列には、すでに重複が確認された値のみが格納されているため、そのまま出力します。
コードと解説
【コード】
まずコードを示します。
Sub DetectDuplicate2()
' 変数宣言
Dim wb As Workbook
Dim ws As Worksheet
Dim last_row As Long ' データの最終行
Dim data_rng As Range ' データ範囲
Dim data_arr As Variant ' データ範囲を格納する配列
Dim base_row As Long ' 比較元の行インデックス
Dim check_row As Long ' 比較先の行インデックス
Dim base_value As String ' 現在の基準値
Dim check_value As String ' 現在の検証値
Dim duplicate_values_arr() As String ' 重複値格納用配列
Dim duplicate_rows_arr() As String ' 重複値の行番号格納用配列
Dim duplicate_count As Long ' 重複発生件数
Dim duplicate_arr_index As Long ' 重複情報配列用インデックス
' ワークブックとワークシートを取得する
Set wb = ThisWorkbook
Set ws = wb.Worksheets(1)
' データの最終行を取得する
last_row = ws.Cells(ws.Rows.Count, 1).End(xlUp).Row
' A2から最終行までを配列に読み込む(二次元配列)
Set data_rng = ws.Range(ws.Cells(2, 1), ws.Cells(last_row, 1))
data_arr = data_rng.Value
' 重複情報格納用配列を初期化する
ReDim duplicate_values_arr(1 To 1)
ReDim duplicate_rows_arr(1 To 1)
duplicate_count = 0
' データ配列の各行を順にチェックする
For base_row = 1 To UBound(data_arr, 1)
' 基準行の値を取得する
base_value = CStr(data_arr(base_row, 1))
' その後ろの行と比べる
For check_row = base_row + 1 To UBound(data_arr, 1)
' 検証行の値を取得する
check_value = CStr(data_arr(check_row, 1))
' 値が一致したら重複として処理する
If base_value = check_value Then
' 既に登録済みかどうかを確認する
duplicate_arr_index = 0
For duplicate_arr_index = 1 To duplicate_count
If duplicate_values_arr(duplicate_arr_index) = base_value Then
Exit For
End If
Next duplicate_arr_index
' 初めての重複なら配列に新規登録する
If duplicate_arr_index > duplicate_count Then
duplicate_count = duplicate_count + 1
ReDim Preserve duplicate_values_arr(1 To duplicate_count)
ReDim Preserve duplicate_rows_arr(1 To duplicate_count)
duplicate_values_arr(duplicate_count) = base_value
duplicate_rows_arr(duplicate_count) = _
CStr(base_row + 1) & "," & CStr(check_row + 1)
' 既に登録済みなら行番号だけを追加する
Else
duplicate_rows_arr(duplicate_arr_index) = _
duplicate_rows_arr(duplicate_arr_index) & "," & CStr(check_row + 1)
End If
End If
Next check_row
Next base_row
' 重複情報を出力する
For duplicate_arr_index = 1 To duplicate_count
Debug.Print duplicate_values_arr(duplicate_arr_index) & _
" " & duplicate_rows_arr(duplicate_arr_index)
Next duplicate_arr_index
End Sub
【出力結果】
このコードを実行すると、次の結果が返ります。前節の方法1と同じ結果です。
解説していきます。
' 変数宣言
Dim wb As Workbook
Dim ws As Worksheet
Dim last_row As Long ' データの最終行
Dim data_rng As Range ' データ範囲
Dim data_arr As Variant ' データ範囲を格納する配列
Dim base_row As Long ' 比較元の行インデックス
Dim check_row As Long ' 比較先の行インデックス
Dim base_value As String ' 現在の基準値
Dim check_value As String ' 現在の検証値
Dim duplicate_values_arr() As String ' 重複値格納用配列
Dim duplicate_rows_arr() As String ' 重複値の行番号格納用配列
Dim duplicate_count As Long ' 重複発生件数
Dim duplicate_arr_index As Long ' 重複情報配列用インデックスここでは、コード内で使用する変数が宣言しています。
変数は Dim 変数名 As データ型 の構文で宣言します。これにより、各変数は As 以降で指定したデータ型の値を格納できるようになります。
具体的には、現在のワークブックやワークシートを操作するためのオブジェクト型の変数、処理対象のデータを保持する配列、比較のための行インデックス、検出された重複値とその出現行を記録する配列などを宣言しています。
また、コードの可読性を高めるため、変数は用途別にグループ化して記述しています。こうすることで、どの変数がどの処理に関わっているのかが一目で把握できるようになります。
なお、各データ型の意味は下表のとおりです。
| データ型 | 種類 | 意味 |
|---|---|---|
Workbook | オブジェクト型 | 現在のワークブックやデータが格納されているワークブックを表すオブジェクトです。 |
Worksheet | オブジェクト型 | データが格納されているワークシートを表すオブジェクト型です。 |
String | 文字列型 | ファイルパスや名前など、テキスト情報を格納する文字列型です。 |
Long | 数値型 | -2,147,483,648 〜 2,147,483,647 の範囲の整数を格納できる数値型です。 |
Variant | 汎用型 | 任意のデータ型を格納できる柔軟な型で、配列や複数の型に対応する場面で使用されます。 |
' ワークブックとワークシートを取得する
Set wb = ThisWorkbook
Set ws = wb.Worksheets(1)ここでは、マクロを含んでいるワークブック(ThisWorkbook)から、最初のワークシート(インデックス番号 1)を取得して、変数 ws に代入しています。
通常、Excel には複数のワークシートが存在するため、どのシートを対象に処理を行うかを明示する必要があります。
インデックス 1 は、左端にあるシートを意味します。たとえば、シートの並び順が「Sheet1」「Sheet2」「Sheet3」であれば、「Sheet1」が対象になります。
このようにワークシートを変数に代入しておくことで、以降の処理では、変数 ws を通じてワークシートを操作できるようになり、毎回 Worksheets(1) と書かずに済むため、コードの可読性と保守性が向上します。
' データの最終行を取得する
last_row = ws.Cells(ws.Rows.Count, 1).End(xlUp).Rowここでは、A列の最終行番号を取得しています。
ws.Rows.Count はシート内の総行数(通常は 1,048,576)を意味し、ws.Cells(ws.Rows.Count, 1) によって、A列の最下部セルが参照されます。
そこから End(xlUp) を使って上方向に値が入力されているセルを探し、最初に見つかったセルの行番号を last_row に格納しています。
この例の場合は、last_rowには11が代入されます。
' A2から最終行までを配列に読み込む(二次元配列)
Set data_rng = ws.Range(ws.Cells(2, 1), ws.Cells(last_row, 1))
data_arr = data_rng.Valueここでは、A列の2行目から最終行までのデータを範囲として取得し、配列 data_arr に読み込んでいます。
このように範囲を Range オブジェクトとして取得し、そこから .Value を代入することで、Excelのセル範囲を二次元配列として効率的に扱うことができます。
読み込まれる配列は、1行目がシートの2行目に、2行目がシートの3行目に対応する構造になっており、このあと出てくる処理では、「何行目か」を求める際に +1 の補正が行われます。
また、セルを1つずつ読み込むよりも、一括で配列化して処理することで、パフォーマンスが大きく向上します。これは、VBAにおける高速化の基本的な考え方のひとつです。
' 重複情報格納用配列を初期化する
ReDim duplicate_values_arr(1 To 1)
ReDim duplicate_rows_arr(1 To 1)
duplicate_count = 0ここでは、重複した値とその行番号を記録するための2つの配列を初期化しています。
ReDim は配列のサイズを指定し直す命令で、1 To 1 とすることで、要素を1つだけ持つ配列として初期化されます。
この段階ではまだデータは何も登録されていないため、必要最小限のサイズで始めておき、重複が見つかるたびに ReDim Preserve によってサイズを拡張していく設計になっています。
また、duplicate_count は重複が何件見つかったかをカウントするための変数で、初期値として 0 を代入しています。
' データ配列の各行を順にチェックする
For base_row = 1 To UBound(data_arr, 1)
' 基準行の値を取得する
base_value = CStr(data_arr(base_row, 1))
' その後ろの行と比べる
For check_row = base_row + 1 To UBound(data_arr, 1)
' 検証行の値を取得する
check_value = CStr(data_arr(check_row, 1))ここでは、読み込んだデータ配列 data_arr を使って、すべての行のペアを比較するためのループ処理を開始しています。
外側のループでは、base_row を1から順に動かしながら、比較の基準となる値(base_value)を取得しています。
内側のループでは、check_row を base_row + 1 から始めることで、すでに比較済みの行との重複チェックを避けるようになっています。
こうすることで、同じペアを2回比較する無駄を省きつつ、重複を一方向から効率よく検出する設計になっています。
各ループ内では、それぞれの値を文字列型(String)として変数に格納し、その後、一致を確認する処理を行っています。
' 値が一致したら重複として処理する
If base_value = check_value Then
' 既に登録済みかどうかを確認する
duplicate_arr_index = 0
For duplicate_arr_index = 1 To duplicate_count
If duplicate_values_arr(duplicate_arr_index) = base_value Then
Exit For
End If
Next duplicate_arr_indexここでは、比較対象の2つの値(base_value と check_value)が一致した場合に、その値がすでに重複として登録されているかどうかを確認する処理を行っています。
まず、duplicate_arr_index に 0 を代入し、続いて 1 から duplicate_count までループすることで、すでに登録された重複値の一覧(duplicate_values_arr)をチェックします。
ループ内で一致する値が見つかれば、その時点で Exit For により繰り返しを終了します。
結果として、duplicate_arr_index が 1 〜 duplicate_count の範囲にあれば「すでに登録済み」、duplicate_count + 1 の位置まで進んだ場合は「未登録」という判定になります。
このようにして、重複の初出かどうかを判定しているのが、この処理のポイントです。
' 初めての重複なら配列に新規登録する
If duplicate_arr_index > duplicate_count Then
duplicate_count = duplicate_count + 1
ReDim Preserve duplicate_values_arr(1 To duplicate_count)
ReDim Preserve duplicate_rows_arr(1 To duplicate_count)
duplicate_values_arr(duplicate_count) = base_value
duplicate_rows_arr(duplicate_count) = _
CStr(base_row + 1) & "," & CStr(check_row + 1)
Else
' 既に登録済みなら行番号だけを追加する
Else
duplicate_rows_arr(duplicate_arr_index) = _
duplicate_rows_arr(duplicate_arr_index) & "," & CStr(check_row + 1)
End If
End If
Next check_row
Next base_rowここでは、前の判定結果に基づき、重複した値が初めて見つかったものか、すでに登録済みのものかによって処理を分けています。
もし、配列にまだ登録されていない重複値であれば、duplicate_count を1つ増やし、uplicate_values_arr と duplicate_rows_arr のサイズを ReDim Preserve で拡張します。
そして、重複していた2つの行番号(基準行と検出行)をカンマ区切りで文字列として記録します。
一方、すでに登録されている重複値であれば、新たに見つかった行番号だけを追記します。
このようにして、同じ値が登場するたびに、行番号の一覧がカンマ区切りで蓄積されていく構造になっています。
' 重複情報を出力する
For duplicate_arr_index = 1 To duplicate_count
Debug.Print duplicate_values_arr(duplicate_arr_index) & _
" " & duplicate_rows_arr(duplicate_arr_index)
Next duplicate_arr_indexここでは、検出した重複値と対応する行番号の一覧を、イミディエイトウィンドウに出力しています。
具体的には、ループを回しながら、各インデックスに格納された値と、カンマで区切られた行番号の文字列を Debug.Print で表示しています。
この処理によって、どの値がどの行に重複していたかを確認できるようになります。
以上で、総当たり比較方式による重複検出コードの解説は終了です。
VBAスキルアップの参考情報
近年は、ChatGPTをはじめとするAIの登場によって、学習のスタイルが大きく変わりました。
分からないことがあれば、AIに尋ねれば答えがすぐに見つかる時代です。
とはいえ、AIを使いこなすには、自分自身の基本的な知識や理解力が欠かせません。
全体像をつかむためには、やはり書籍などで体系的に学んでおくことが今でも有効です。
そのうえでAIを活用すれば、自分の理解度に合わせた的確な解説や、応用のヒントを得ることができます。
「学んで基礎を築く → AIで補い発展させる」──このサイクルを重ねることで、VBAスキルは着実に高まっていくでしょう。
VBAのスキルアップ
VBAを学び始めるなら
入門書は、どれを選んでも大きな差はないように感じます。
どれを選ぶかに悩むことに時間をかけるよりも、まずは手頃な一冊を手に取って進めてみるのがおすすめです。
もし迷ったときには、私はインプレス社の「いちばんやさしい」シリーズを選ぶことが多いです。
基礎を超えて力をつけたいなら
私は上級者を目指していましたので、入門書にとどまらず、このような内容の濃い一冊を選んで学んでいました。
今は誰でもAIを活用できる時代になりましたが、上級者を目指す方にとっては、AIをより上手に活用するという意味でも、こうした本は今なお価値があります。
このレベルの本を一冊持っておくことに、損はないでしょう。
資格で能力を証明したいなら
VBAのプログラミング能力を客観的に示したい場合には「VBAエキスパート試験」があります。
特に「スタンダード」の方は上級者向けです。
あなたが社内業務の改善を行う立場であっても、VBAで作成したシステムをお客様に納める立場であっても、この資格は信頼や安心につながるでしょう。
以下の公式テキストが販売されています。
プログラミングの一般教養
「独学プログラマー」というプログラミングの魅力を解説した書籍があります。
これはVBAではなくPythonを題材としていますが、プログラミングの基本的な知識や思考法、仕事の進め方まで幅広く学べます。
今はAIにコードを尋ねれば、答えが返ってくる時代です。
しかし、この本からは「コード」以上に、プログラミングに向き合う姿勢や考え方を学ぶことができるでしょう。
こちらの記事でも紹介しています。もしよろしければご覧ください。
【初心者歓迎】無料相談受付中

いつもありがとうございます!
限られた時間をより良く使い、日本の生産性を高めたい──
みんなの実用学を運営するソフトデザイン工房では、業務整理や業務改善アプリケーション作成のご相談を承っております。
お気軽にご相談ください。
こちらの記事でも紹介しております。
おわりに

ご覧いただきありがとうございました!
今回の記事では、「Mac環境でデータの重複を検出する方法」を解説しました。
お問い合わせやご要望がございましたら、「お問い合わせ/ご要望」フォームまたはコメント欄よりお知らせください。
この記事が皆様のお役に立てれば幸いです。
なお、当サイトでは様々な情報を発信しております。よろしければトップページもあわせてご覧ください。
この記事を書いた人




